 Know Easy
Know Easy 

Google Associate Cloud Engineer、Profesional Cloud Developperの試験ではKubenetesの理解は必須と言えます。
試験に挑戦する前に、Kubernetesの基礎をしっかりと理解したい方は、このブログに目を通していただければ幸いです。
Kubernetesの基本概念から始めて、Google Cloudでの活用方法までを詳しく解説します。
Kubenetesとは
Kubernetes(クーバネティス)は、コンテナ化されたアプリケーションのデプロイメント、スケーリング、および管理を自動化するオープンソースのコンテナオーケストレーションプラットフォームです。
このシステムは、クラウド上やオンプレミスのインフラストラクチャ上で、複数のコンテナを効果的かつ柔軟に管理できるように設計されています。
Kubernetesは、アプリケーションの高可用性やスケーラビリティの向上、継続的なデリバリー、セルフヒーリングなどの機能を提供し、コンテナ化された環境でのアプリケーションの展開と運用を容易にします。
公式の図から簡単解説
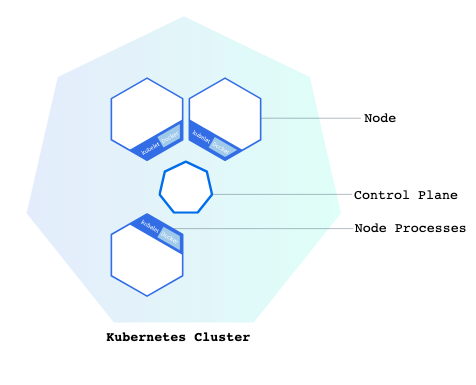

Control Plane(コントロールプレーン)
「コントロールプレーン」は、Kubernetesのクラスタの制御、管理、監視を担当する全体の要素を指します。
マスター(クラスターの管理を担当する)
マスターはアプリケーションのスケジューリングや、望ましい状態の維持、アプリケーションのスケーリング、更新のロールアウトなどを行うノードです。
実行中アプリケーションをホストするために使用されるノードとクラスタを管理します。
Control Plane(コントロールプレーン)とマスターの違い
「コントロールプレーン」はクラスタ全体の制御に関わる様々なコンポーネントを指し、「マスター」は主にKubernetesのクラスタ制御に関わる特定のコンポーネントを指します。
コントロールプレーンはマスターを含む、もう少し大きな概念となります。
ノード
Kubernetesクラスタのワーカーマシンとして機能するVMまたは物理マシンのことです。
ノードは複数のPodを持つことが可能で、ノードが停止すると、そのノードで実行されているPodも失われます。
Kubelet(キューブレット)
Kubernetesマスターとノード間の通信を担当するプロセスです。
マシン(ノード)上で実行されているPodとコンテナを管理します。
Kubernetesノード上で実行される必須のコンポーネントで、kubeletがノードに存在することにより、ワーカーノードとマスターノードの通信を可能にし、さらにPodの管理が可能になります。
Kubenetesの配置
Kubernetesクラスターは、物理マシンまたは仮想マシンのどちらにも配置することが可能です。
Deployments(デプロイメント)
Deployment(デプロイメント)は、コンテナ化されたアプリケーションの管理とスケーリングを容易にするKubernetesのリソースオブジェクトです。
Deployments:アプリケーションの宣言的定義
アプリケーションのコンテナイメージ、レプリカ数、更新戦略などのパラメータを含む宣言的な定義を提供します。
これにより、ユーザーは目標の状態を宣言し、Kubernetesがそれを達成するために必要なステップを自動的に実行します。
ローリングアップデートとロールバック
Deploymentはアプリケーションの更新を管理し、新しいバージョンへのローリングアップデートをサポートします。
もしアップデートに問題があれば、ユーザーは簡単に前の状態にロールバックすることができます。
自動的なレプリカ管理
Deploymentは指定された数のレプリカ(同じコピーのアプリケーション)を確実に実行します。
もしレプリカがクラッシュしたり追加されたりした場合、Deploymentは自動的に調整して目標のレプリカ数を保ちます。
自動修復機能(セルフヒーリング)
Deploymentはアプリケーションのセルフヒーリングをサポートし、クラッシュしたPodを検出すると自動的に新しいPodを起動して復旧します。
※ただし、自動修復機能はデフォルトでサポートされているわけではありません。
Restart Policy(リスタートポリシー)
ポッドの再起動ポリシーが設定されている場合、異常な状態にあるPodが自動的に再起動されます。
これは、自動修復を行う1つの方策です。
リソース制約の監視
クラスタ内でPodが必要なリソース制約を満たしているかどうかが監視されている場合、これに基づいて異常な状態にあるPodが自動的に再起動されることがあります。
クラスタ内でPodを監視するにはCloud Loggingなどの外部メトリクスの利用が有効です。
Readiness Probe(準備確認プローブ)
Readiness Probe, Liveness Probe, Startup Probeの内容はProfessional Cloud Developperの領域になります。
Readiness Probeは、Podがトラフィックを受け入れるかどうかを確認します。
もしPodが「Readiness Probe未達成」の状態であれば、ServiceからのトラフィックがそのPodに流れず、ロードバランサーなどがそのPodにトラフィックを転送しないようになります。
これにより、アプリケーションが正常に動作する前にトラフィックを送られることを防ぎます。
Liveness Probe(生存確認プローブ)
Liveness Probeは、Pod内のコンテナが正常に動作しているかどうかを確認します。
もしPodが「Liveness Probe未達成」の状態にあれば、KubernetesはそのPodを再起動します。
これにより、アプリケーションやプロセスがクラッシュした場合に自動的に再起動され、高い可用性が確保されます。
Startup Probe(起動プローブ)
Startup ProbeはPod が起動した直後にのみ実行され、アプリケーションが正常に起動し、利用可能な状態になるまでの適切な時点でのみ成功するように設定できます。
Startup Probeは立ち上げに時間がかかることが想定されるアプリケーションなどに利用されます。
Readiness ProbeとStartup Probeの使い分け
アプリケーションが通常のトラフィックを受け入れられるかどうかを確認する場合、
または一時的なエラーが発生する可能性がある場合、Readiness Probe を使用します。
アプリケーションが起動し、利用可能な状態になるまでの遅延がある場合、Startup Probe を使用します。
Readiness ProbeとLiveness Probeの確認メソッド
これはどちらも、HTTP、TCP、またはExec方式で設定できます。
例えば、TCP方式の場合、特定のポートにTCP接続を試み、成功すれば正常とみなします。
参考
下記の例は/healthzエンドポイントに対してHTTPリクエストを送り、5秒ごとにReadiness ProbeとLiveness Probeが実行される。 Readiness Probeが初回に5秒遅れて開始し、Liveness Probeが初回に10秒遅れて開始するように設定されています。
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp-container
image: myapp:latest
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
Kubenetes EngineではCloud Loggingはデフォルトで有効になっている
GCP上でKubernetes Engineを使用している場合、通常はデフォルトでCloud Loggingが有効になっており、設定が変更されていない限り、特別な手順は必要ない。
Cloud Loggingの動き
Cloud Loggingは、Kubernetesクラスタ内の各ノードにエージェント(fluentd)をデプロイしてログを収集します。
各ノード上で実行されているPodからログを収集しCloud Loggingに転送します。
もちろんではありますが、Kubenetes EngineのノードにPodに対してデフォルトでCloud LoggingがMoonitoring Agentをデプロイしてログや稼働状況を監視しますが、これはDeamonSet(デーモンセット)でデプロイされます。
Pod
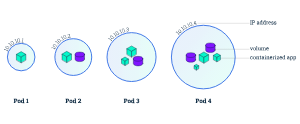
Podとは
Podはノード上で動作します。
Podは、1つ以上のアプリケーションコンテナ(Dockerなど)のグループとそれらのコンテナの共有リソースを表すKubernetesの抽象概念であり、固有のクラスタ内IPアドレスを持ちます。
(ServiceなしではIPアドレスは外部に公開されません。)
Podに含まれるものとして下記のようなものがある。
- 共有ストレージ(ボリューム)
- ネットワーキング(クラスターに固有のIPアドレス)
- コンテナのイメージバージョンや使用するポートなどの、各コンテナの動作に関する情報
Kubernetes Service
ServiceはKubernetesクラスタ内での通信や外部からのアクセスを抽象化し、アプリケーションをより柔軟で耐障害性のあるものにする役割を果たします。

Serviceの具体的な役割
サービスの具体的な役割は以下のようになります。
ルーティング
Podにトラフィックをルーティングします。
Serviceはアップデート中に利用可能なPodのみにトラフィックを負荷分散します。
Podは通常動的にスケールインやスケールアウトするため、Serviceを介してアクセスすることで動的な変更に柔軟に対応できます。
一意なDNSエントリー
Serviceには、クラスタ内部で一意なDNSエントリーがあります。
他のPodはService名を使用して、対応するPodにアクセスできます。
このDNSエントリーはServiceが作成されたときに自動的に生成されます。
ClusterIP(仮想のIPアドレス)の付与
クラスター内の内部IPでServiceを公開する。
Serviceはクラスター内からのみ到達可能になる。
ロードバランシング
Serviceはクラスタ内のPodに対するトラフィックを均等に分散するロードバランサーの機能を果たします。
複数のPodが同じServiceにバインドされている場合、トラフィックが均等に分散される。
外部サービスとしての使用
LoadBalancerタイプのServiceは、クラスタ外からアクセス可能な外部ロードバランサーを作成します。
これにより、クラスタ内のPodに外部からアクセスできるようになります。
NodePort(ノードポート)
NATを使用して、クラスター内の選択された各ノードの同じポートにServiceを公開します。
<NodeIP>:<NodePort>を使用してクラスターの外部からServiceにアクセスできるようにします。
これはClusterIPのスーパーセットです。
LoadBalancer(ロードバランサー)
現在のクラウドに外部ロードバランサを作成し(サポートされている場合)、Serviceに固定の外部IPを割り当てます。
これはNodePortのスーパーセットです。
ExternalName()
仕様のexternalNameで指定した名前のCNAMEレコードを返すことによって、任意の名前を使ってServiceを公開します。
プロキシは使用されません。このタイプはv1.7以上のkube-dnsを必要とします。
ローリングアップデート
ReplicaSet(レプリカセット)
Kubernetesにおけるオーケストレーションの概念の一つ。
特定の数のレプリカ(同じコピーのアプリケーションコンテナ)が稼働していることを保証するためのリソースオブジェクト。
もしレプリカの数が指定した数よりも少ない場合、ReplicaSetは新しいレプリカを起動して指定した数を維持しようとします。
逆に、余分なレプリカがある場合は、不要なレプリカを削除します。
ReolicaSetのスケーリング
ReplicaSetは手動または自動でスケーリングすることができます。
ReplicaSetの手動スケーリング
手動でのスケーリングでは、ユーザーがReplicaSetのレプリカ数を変更します。
ReplicaSetの自動スケーリング
自動スケーリングでは、CPU使用率やメモリ使用率などのメトリクスに基づいて、システムが自動的にスケーリングの判断を行う。
DaemonSet(デーモンセット)
各ノード上で特定のPodを一つずつ常に動作させるように設計されている。
デーモンセットの一般的な用途は、クラスタ内の各ノード上で同じサービスやプロセスが常に動作することを確実にすることで、これにより、分散型のサービスやログ収集エージェントなど、各ノードで必要なサービスが提供されます。
デーモンセットが定義されている場合、新しいノードがクラスタに追加されると、そのノード上でデーモンセットに指定されたPodが自動的にスケジューリングされ、実行されます。
デーモンセットが定義されていない場合は、デーモンセットは作成されません。
DeamonSet(デーモンセット)が向いているユースケース
- ログ収集エージェントやネットワークプロキシのデプロイ
- セキュリティエージェントやエンドポイントプロテクション
- システムワイドなサービスやバックグラウンドタスク
StatefullSet(ステートフルセット)
Kubernetesの名前空間
Kubernetesの名前空間(Namespace)は、クラスタ内のリソースを論理的に分離し、異なるプロジェクト、チーム、または環境などで使われるリソースを区別するための仕組み。
名前空間はクラスタ内で一意であり、同じ名前の名前空間を複数作成することはできない。
名前空間を使用することで、クラスタ内で多くの異なるアプリケーションやチームが同時に動作していても、それらを論理的に分離し、整理された形で管理することができる。
論理的な分離
名前空間はリソース(Pod、Service、ConfigMapなど)をグループ化し、論理的な分離を提供します。
異なる名前空間内のリソースは、同じ名前のリソースと競合することなく共存できます。
権限の制御
名前空間は、クラスタ内でのアクセス権限を制御するために使用できます。
各名前空間にはIAMとは異なる独自のセキュリティコンテキスト(RBAC:ロールベースドアクセスコントロール)があり、その名前空間内のリソースにアクセスするためには適切な権限を設定できます。
環境やプロジェクトの分離
異なるプロジェクト、チーム、環境(開発、ステージング、本番など)ごとに名前空間を作成することで、それぞれのグループが独立して作業できます。
これにより、リソースの管理やトラブルシューティングが容易になります。
↑Development, Staging, Productionなどの各種環境は、Kubenetesの名前空間の機能で分けることは可能かもしれませんが、Googleではこれらのようなケースにおいては、プロジェクトレベルで分離することが推奨されており、一般的にもそのようにするのが正しいので、あくまでできるくらいの認識、また試験の回答にプロジェクトで分ける選択肢がない場合に選択すると良いでしょう。
クラスタ内のリソース整理
クラスタ内に多くのリソースがある場合、名前空間を使用してそれらを整理し、特定のコンポーネントやアプリケーションに関連するリソースをグループ化できます。
リソース名の重複の回避
異なる名前空間で同じ名前のリソースを使用することができます。
これにより、クラスタ全体で一意の名前を持つリソースが複数存在できます。
参考:名前空間の作成
$ kubectl create namespace <namespace-name>

