 Know Easy
Know Easy 

議事録作成は面倒くさい作業ですよね。
文字起こしが自動できて、議事録がさくっとできるならそれ以上のことはありません。
今回は今話題のchatGPTのwhisperモデルを利用して、文字起こしから議事録の作成までできるのか試してみました。
議事録ツールとして使えるかどうか結論から
結論ですが、、、
議事録ツールとして利用するのは相当厳しいと感じました。
動作させる実行プログラムサンプル
mp3から文字起こしを行う
import openai
# 入力する音声ファイル
fname = "your-file-name.mp3"
# APIキーが格納されたファイルへのパス
openai.api_key_path = 'your-file-name.txt'
audio_file = open(fname, "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
txt = transcript['text']
f = open(fname + ".txt", "w")
f.write(txt)
f.close()
これを実行すれば、mp3データから文字起こしを行ったtxtファイルが作成されます。
(APIキーについてわからない方はこちら)APIキーの読み込み方
※スクリーンショットのAPIはすでに失効しているため利用できません。
1.まずはシークレットキーを発行します
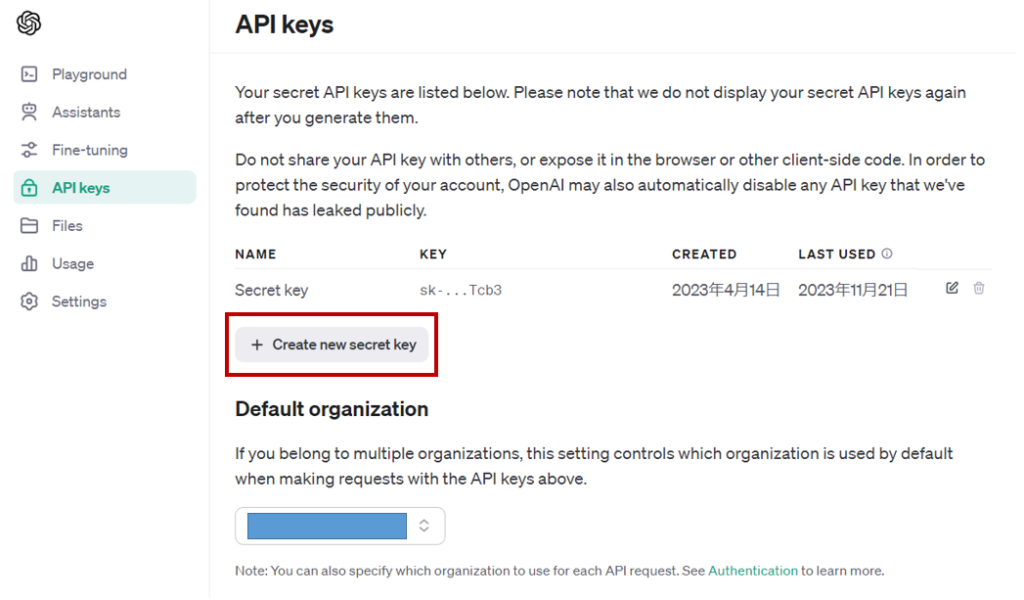
2.次にキーに名前を付けます
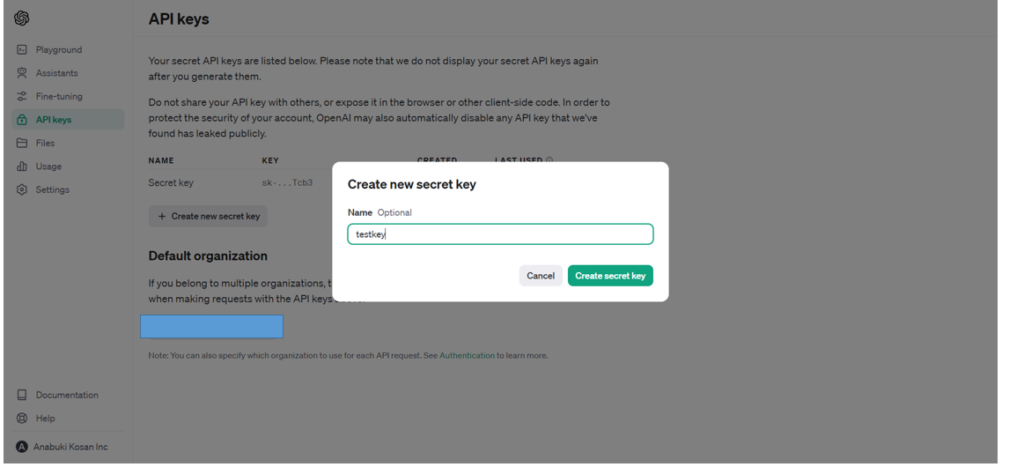
3.次にキーが発行されるので、クリップボードへコピーしましょう。
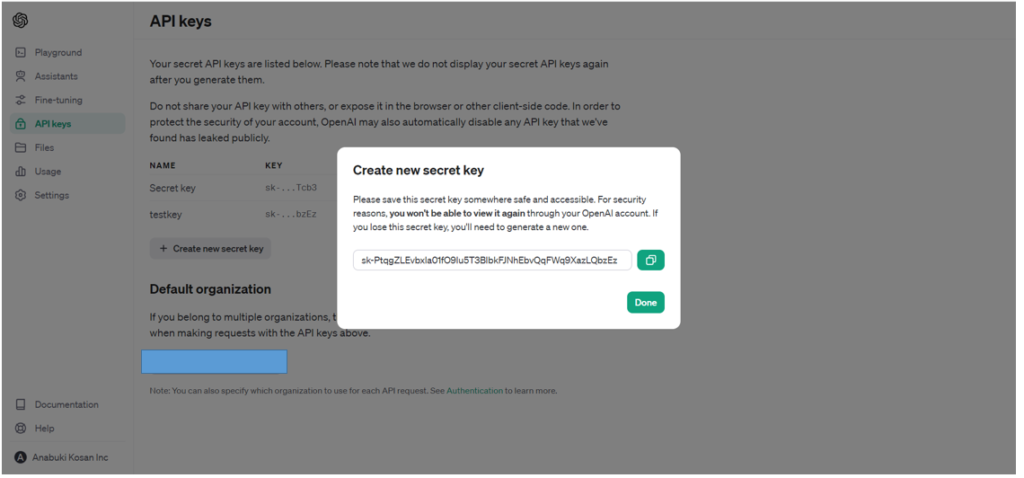
4. 最後にメモ帳アプリでキー用の.txtファイルを作成しましょう。
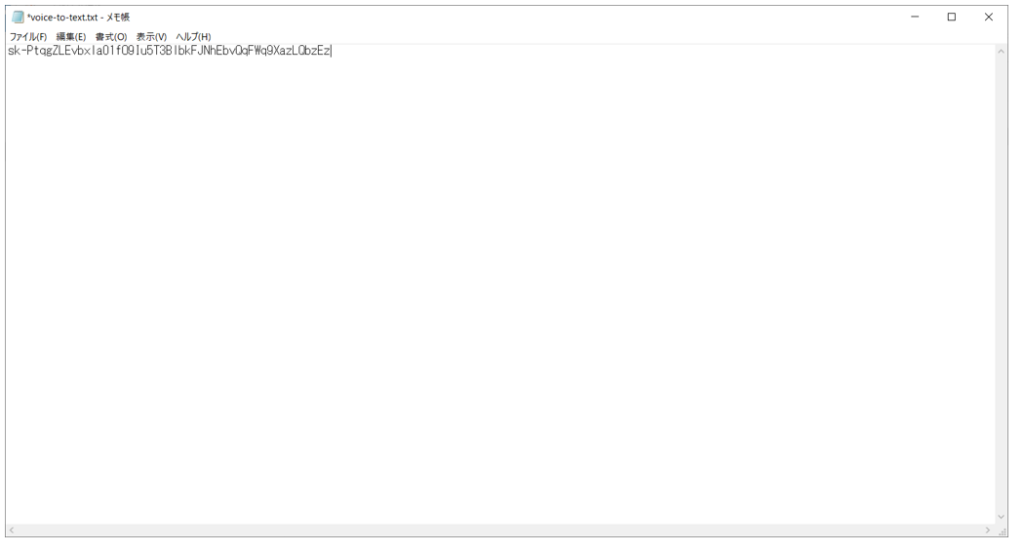
.txtファイルを改行する
chatGPTで吐き出しただけのファイルは横長でとても見ずらいので、空白タブごとに改行します。
# テキストファイルから文字列を読み込む
fname_with_extension = fname + ".txt"
with open(fname_with_extension, 'r', encoding='cp932') as file:
content = file.read()
# 空白またはタブで区切られた単語ごとに改行する
words = content.split() # 空白文字(スペース、タブ、改行)で区切る
new_content = '\n'.join(words)
# 改行後の文字列をファイルに書き込む
with open(fname_with_extension, 'w', encoding='utf-8') as file:
file.write(new_content)
ファイルから議事録を作成する
# ファイル名のリスト(出来上がったファイルを読み込ます)
file_names = ["your-text.txt"]
# 議事録
transcript = "与えられたテキストから議事録を作成して下さい。"
# 各ファイルのテキストを読み取り、議事録に結合
for file_name in file_names:
with open(file_name, "r", encoding="utf-8") as file:
transcript += file.read()
# ChatGPTにテキストを渡して生成されたテキストを取得
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # 使用するモデルの指定
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": transcript}
],
max_tokens=1000 # 生成されるテキストの最大トークン数
)
# ChatGPTの生成テキストを取得
generated_text = response['choices'][0]['message']['content']
# 議事録を出力
with open("transcript_with_gpt.txt", "w", encoding="utf-8") as output_file:
output_file.write(generated_text)
print("議事録が生成されました。")
議事録の元のデータが微妙だったの、ビルゲイツさんのWikiの内容を読ませて議事録として出すようにしてみた例です。
使いずらい大きな理由2点

1. 25MB(メガバイト)読み込みの制限が辛い
chatGPTのWhisperモデルはmp4またはmp3からテキスト化する際に25MBまでのサイズしか扱えません。
実際に、1時間のZoom会議をMP4ファイルに変換して、そこからさらにmp3ファイルに変換したところ、小さくても50mbを超えてきます。
ビジネスの現場では打ち合わせは体感ですがおおよそ45~60分で行うのがスタンダードになってくることから、読み込ませて文字起こしを行うにも、ファイルの分割は必須となりそうです。
まず、この点が使いずらい点の1つ目です。
実際に25mbを超えるファイルでリクエストを送ると返ってくるレスポンス
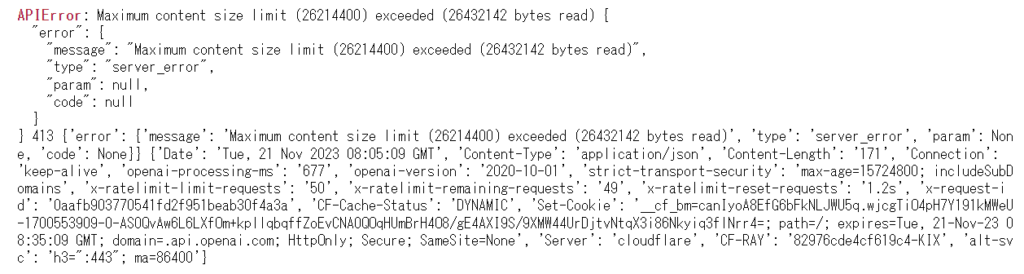
2. ファイルを文字起こししてもとても読み込みきれない
前述のように、文字起こしした.txtファイルもmp3データ同様に、読み込みしても会議のすべてを読み込めるわけではありません。
この点も大きな問題点になるでしょう。
実際にリクエストを送った際のエラー

まとめ
chatGPTは便利なのは誰もが認めるところでしょう。
ただ、「議事録を作成する」という目的を達成するには越えなければならない課題がたくさんありそうです。

